AS Level Biology 9700
6. Nucleic acids and protein synthesis
Written by: Rhia Sakthivel
Formatted by: Pranav I
Index
6.1 The molecule of life
- The genetic material in living things must have:
- The ability to store information → set of instructions to control cell behavior
- The ability to copy itself accurately → no information can be lost
6.2 The structure of DNA and RNA
- Nucleic acids are macromolecules
- Nucleic acid is a polymer formed of many repeating nucleotide monomers
- There are 2 types of nucleic acids:
- DNA (double stand) → deoxyribonucleic acids
- RNA (single stand) → ribonucleic acids
Nucleotide structure
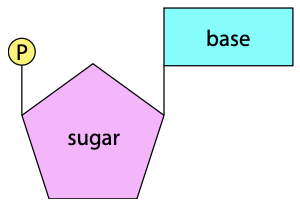
Nitrogenous bases
- 4 bases found in DNA
- Adenine (A)
- Guanine (G)
- Thymine (T)
- Cytosine (C)
- In RNA, instead of thymine, we have uracil (U)
- Adenine and guanine are purines with a double-ring structure
- Cytosine, thymine, and uracil are pyrimidines with a single-ring structure
Pentose sugar
- Pentose sugar has 5 carbon atoms
- The pentose sugar determines the type of nucleotide
- Ribose sugar → ribonucleotide
- Deoxyribose sugar → deoxyribonucleotide
- The difference is that deoxyribose has one less oxygen atom in the molecule
Phosphate group
- Makes the nucleic acid molecule acidic in nature
ATP structure
- Adenosine triphosphate (ATP) is NOT a part of DNA or RNA
- However, it is a nucleotide
\[
\text{Adenine} + \text{Ribose} \rightarrow \text{Adenosine}
\]
\[
\text{Adenosine} + \text{Phosphate group (P)} \rightarrow \text{Adenosine monophosphate (AMP)}
\]
\[
\text{Adenosine monophosphate (AMP)} + \text{2 Phosphate groups (2P)} \rightarrow \text{Adenosine triphosphate (ATP)}
\]
- Role of ATP:
- Provide energy for the cell
- E.g. active transport, endocytosis, exocytosis
Structure of a DNA molecule
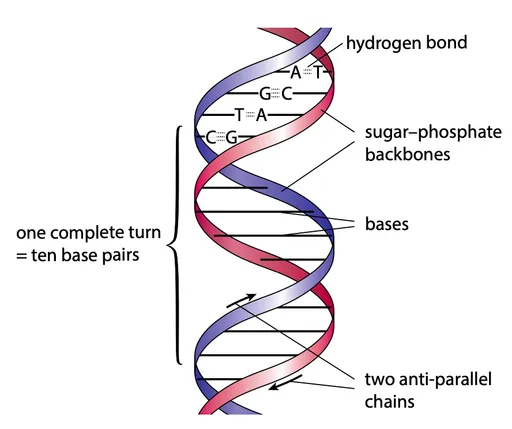
- One DNA molecule consists of two polynucleotide chains
- The bases in one chain are attracted to the bases of the other chain by hydrogen bonding between the bases
- This holds the chains together.
- The two chains coil around each other to form a double helix
- The strands run in opposite directions → antiparallel
- Each strand has a sugar-phosphate backbone with phosphodiester bonds
- A = T and G ≡ C → complementary base pairing, meaning the 2 strands are complementary as well
- A links with T by two hydrogen bonds; G links with C by three hydrogen bonds
- A purine always pairs with a pyrimidine
- The distance between the two backbones is therefore constant and always three rings wide
- A complete turn of the double helix takes place every 10 base pairs
Store of information
- The information is the sequence of bases → represented by the four letters, A, G, T, and C
- Any sequence is possible within one strand, but the other strand MUST be complementary
- The sequence acts as a coded message
Structure of an RNA molecule
- RNA is a single polynucleotide strand
- Three types of RNA are involved in protein synthesis:
- Messenger RNA (mRNA)
- Transfer RNA (tRNA)
- Ribosomal RNA (rRNA)
- tRNA and rRNA fold into complex structures, while mRNA remains as an unfolded strand
6.3 DNA replication
- Multiple enzymes control replication (you have to know 2 in depth)
- Step 1: unzipping
- DNA helicase enzyme separates the two strands of DNA by the breaking of hydrogen bonds
DNA polymerase
- DNA polymerase is used for the copying process
- DNA polymerase attaches to EACH of the single strands
- It adds one new nucleotide at a time → held by hydrogen bonding to the strand being copied
- DNA polymerase can only copy in the 5′ to 3′ direction along each strand
Leading strand
- One of the original strands is being copied in the same direction as the unwinding process
- The DNA polymerase simply follows the unwinding process, copying the DNA
Lagging strand
- However, in the other strand, the 5′ to 3′ direction of copying is in the opposite direction to the unwinding
- The DNA polymerase has to copy an unwound piece of DNA and then go back and copy the next piece of unwound DNA
- This creates short fragments of copied DNA called Okazaki fragments
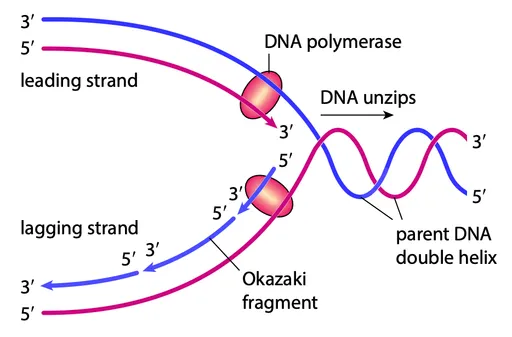
DNA ligase
- DNA ligase connects neighboring nucleotides with phosphodiester bonds to form the sugar-phosphate backbone of the new strand
- Finishes the lagging strand by connecting all the Okazaki fragments
Semi-conservative replication
- This method of copying DNA is called semi-conservative replication
- Each new DNA molecule retains half of the original molecule
- 1 DNA molecule = 1 original strand + 1 newly replicated strand
🚨 DNA polymerase synthesizes new DNA strands, while DNA ligase joins DNA fragments together
6.4 The genetic code
- The sequence of bases in the DNA of a cell is the code for all the proteins of that cell and organism.
- Gene: a sequence of nucleotides that code for a polypeptide
- There are 20 common amino acids found in proteins, and four different bases in DNA to code for them
- The code for each amino acid is a triplet code → consists of three bases
- There are 64 different possibilities for a triplet code
Features of DNA genetic code
- The code is universal
- This means that each triplet codes for the same amino acid in all living things.
- The code has punctuations
- Three of the DNA triplets act as ‘full stops’ in the message
- During protein synthesis, these stop triplets mark the end of a gene.
- Some triplets can act as ‘start signals’, where the process of copying a gene starts
- The code is described as redundant or degenerate
- Some amino acids are coded for by more than one triplet (e.g. ACA & ACG both codes for cysteine)
6.5 Protein synthesis
- DNA is found in the nucleus and proteins are made in ribosomes in the cytoplasm
- mRNA acts as an intermediate molecule to carry information from the nucleus to ribosomes
- “DNA makes RNA and RNA makes protein”
- Transcription → DNA makes mRNA
- Translation → mRNA is decoded to make protein
Transcription
- Takes place in the nucleus where DNA is located
- RNA polymerase is responsible for transcription
- RNA polymerase attaches to the gene’s start point
- DNA is unwound and hydrogen bonds between strands are broken, unzipping the DNA.
- Two single strands are exposed:
- Template strand (transcribed strand): used for RNA synthesis (complementary to RNA)
- Non-transcribed strand: not copied
- A complementary RNA copy of the template strand is made
- RNA contains the base uracil instead of thymine
- The DNA strand will contain START and STOP triplet codes to instruct what part of the DNA needs to be transcribed
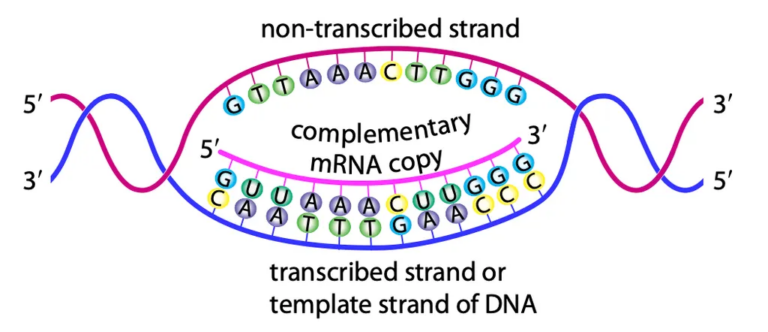
mRNA synthesis
- mRNA is made from free nucleotides in the nucleus
- RNA polymerase
- Moves along the gene, pairing nucleotides with complementary DNA bases via hydrogen bonding
- Joins adjacent nucleotides using phosphodiester bonds
- Once a section is copied, hydrogen bonds between mRNA and DNA break
- Transcription ends when a STOP triplet code is reached, releasing the completed mRNA
- Leaves the nucleus through a nuclear pore in the nuclear envelope
Translation
- mRNA is a complementary copy of the gene coding for the polypeptide
- Triplet: DNA set of three bases coding for an amino acid
- Codon: complementary set of three mRNA bases coding for an amino acid
- Ribosomes facilitate translation and are composed of rRNA and protein, with small and large subunits
- tRNA transfers amino acids to ribosomes for polypeptide synthesis
- One end of tRNA carries a specific amino acid, and the other has an anticodon (three bases complementary to the mRNA codon)
- Enzymes ensure each tRNA carries the correct amino acid
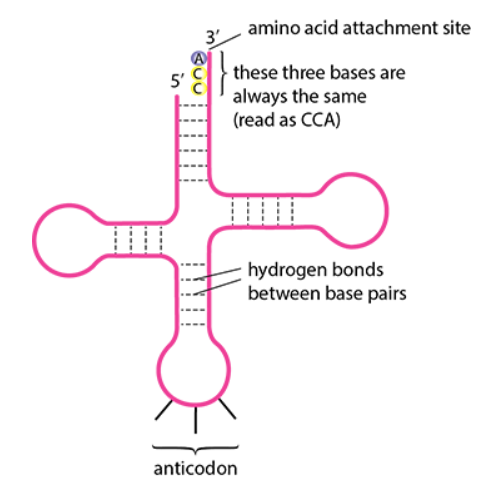
- Translation involves interactions between mRNA, tRNA, ribosomes, and enzymes
- mRNA enters a groove between ribosome subunits, positioning itself to receive tRNA
- First tRNA with an anticodon complementary to the first mRNA codon binds via hydrogen bonding
- Ribosomes can accommodate two tRNAs at a time
- The second tRNA anticodon binds to the next mRNA codon
- Amino acids on adjacent tRNAs form a peptide bond
- First tRNA exits, ribosome shifts one codon, and the next tRNA enters with a new amino acid
- This repeats until a STOP codon (a codon that terminates translation) is reached
- Completed polypeptide detaches, and folds into secondary and tertiary structures
- Folding is aided by specialized proteins
- Polypeptide may enter the ER for transport within the cell
6.6 Gene mutations
- Gene mutation: a change in the nucleotide sequence of a DNA molecule causing altered mRNA, and a change in the primary structure of proteins
- Chromosome mutation: a random and unpredictable change in the structure or number of chromosomes in a cell
- Mutations occur due to:
- Errors during DNA replication (copying errors)
- DNA damage from factors like radiation and other mutagens
- A change in the DNA base sequence may alter the amino acid sequence of the polypeptide it codes for
- Gene mutations are random events and are typically harmful because:
- They may disrupt the polypeptide’s amino acid sequence (primary structure)
- This can alter how the polypeptide folds, changing its tertiary structure and effectiveness
- Mutations in certain genes can lead to cancers
Types of mutations
- Three of the most common gene mutations are:
- Substitution → a base is replaced by a different base
- Deletion → a base is lost and not replaced
- Insertion → a base is added
Substitution
- A substitution mutation occurs when one base in the DNA sequence is replaced by another
- Substitution may or may not affect the amino acid sequence coded by the DNA
- Example of substitution causing a change
- Normal sequence: CAA|TTT|GAA|CCC → valine | lysine | leucine | glycine
- Substituted sequence: CAA|TAT|GAA|CCC → valine | isoleucine | leucine | glycine
- Result: Lysine is replaced by isoleucine
- Example of substitution causing no change
- Normal sequence: CAA|TTT|GAA|CCC → valine | lysine | leucine | glycine
- Substituted sequence: CAA|TTC|GAA|CCC → valine | lysine | leucine | glycine
- Result: No change in the amino acid sequence because both TTT and TTC code for lysine
- Example of substitution causing a change
- The genetic code is degenerate, meaning multiple triplets can code for the same amino acid
Deletion and insertion
- Deletions and insertions are much more likely to be serious than substitutions because they cause frame-shift mutations
- Frame-shift mutations: is a gene mutation caused by the insertion or deletion of nucleotides, which shifts how the genetic code is read, leading to incorrect grouping of triplets
- This shifts the reading frame, altering all triplets (codons) from the mutation point onward
- The resulting sequence codes for incorrect amino acids, making the protein or polypeptide likely non-functional
- For example:
- Normal sequence: TAG|TAG|TAG|TAG|TAG|TAG|TAG|TAG|TAG|TAG|TAG
- Insertion of a base (e.g. C): TAG|TAG|TAG|TAG|CTA|GTA|GTA|GTA|GTA|GTA|GTA
- Deletion of a base: TAG|TAG|TAG|TAG|AGT|AGT|AGT|AGT|AGT|AGT
- Both mutations cause the rest of the sequence to be altered, affecting the entire protein structure and function